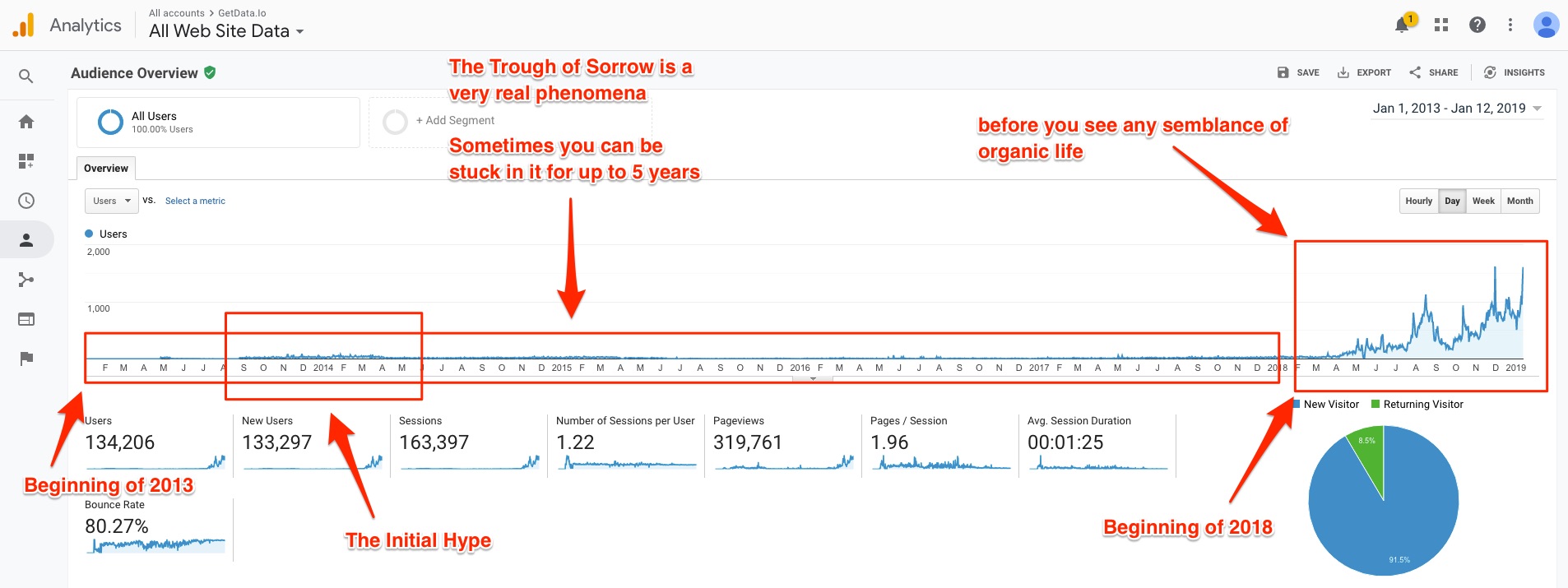
While I was reading through most of the success stories that were published on IndieHackers.com, it occurred to me that my project GetData.IO really took longer than most others to gain significant traction, a full 5 years actually.
The beginning
I first stumbled upon this project back in December 2012 when I was trying to solve two other problems of my own.
In my first problem, I was trying to identify the best stocks to buy on the Singapore Stock Exchange. While browsing through the stocks listed on their website, I soon realize that most stock exchanges as well as other financial websites gear their data presentation towards quick buy and sell behaviors. If you were looking to get data for granular analysis based on historical company performance as opposed to stock price movements, its like pulling teeth. Even then, important financial data I needed for decision making purposes were spread across multiple websites. This first problem lead me to write 2 web-scrappers, one for SGX.com and the other for Yahoo Finance, to extract data-sets which I later combined to help me with my investment decision-making process.
Once I happily parked my cash, I went back to working on my side project then. It was a travel portal which aggregates all the travel packages from tour agencies located in Southeast Asia. It was not long before I encountered my second problem… I had to write a bunch of web-scrapers again to pull data from vendor sites which do not have the APIs! Being forced to write my 3rd, 4th and maybe 5th web-scraper within a single week lead me to put on hold all work and step back to look at the bigger picture.
The insight
Being a web developer, and understanding how other web developers think, it quickly occurred to me the patterns that repeat themselves across webpage listings as well as nested webpages. This is especially true for naming conventions when it came to CSS styling. Developers tend to name their CSS classes the way they would actual physical objects in the world.
I figured if there existed a Semantic Query Language that is program independent, it would provide the benefit of querying webpages as if they were database tables while providing for clean abstraction of schema from the underlying technology. These two insights still prove true today after 6 years into the project.
The trough of sorrow
While the first 5 years depicted in the trend line above seem peaceful due to a lack of activity, it felt anything but peaceful. During this time, I was privately struggling with a bunch of challenges.
Team management mistakes and pre-mature scaling
First and foremost was team management. During the inception of the project my ex-schoolmate from years ago approached me to ask if there was any project that he could get involved in. Since I was working on this project, it was a natural that I would invited him to join the project. We soon got ourselves into an incubator in Singapore called JFDI.
In hindsight, while the experience provided us with general knowledge and friends, it really felt like going through a whirlwind. The most important piece of knowledge I came across during the incubation period was this book recommendation?—?The Founder’s dilemma. I wished I read the book before I made all of the mistakes I did.
There was a lot of hype (see the blip in mid-2013), tension and stress during the period between me and my ex-schoolmate. We went our separate ways due to differences in vision of how the project should proceed shortly after JDFI Demo Day. It was not long before I grew the team to a size of 6 and had it disbanded, realizing it was naive to scale in size before figuring out the monetization model.
Investor management mistakes
During this period of time, I also managed to commit a bunch of grave mistakes which I vow never to repeat again.
Mistake #1 was being too liberal with the stock allocation. When we incorporated the company, I was naive to believe the team would stay intact in its then configuration all the way through to the end. The cliff before vesting were to begin was only 3 months with full vesting occurring in 2 years. When my ex-schoolmate departed, the cap table was in a total mess with a huge chunk owned by a non-operator and none left for future employees without significant dilution of existing folks. This was the first serious red-flag when it came to fund raising.
Mistake #2 was giving away too much of the company for too little, too early in the project before achieving critical milestones. This was the second serious red-flag that really turned off follow up would-be investors.
Mistake #3 was not realizing the mindset difference of investors in Asia versus Silicon Valley, and thereafter picking the wrong geographical location (a.k.a network) to incubate the project. Incubating the project in the wrong network can be really detrimental to its future growth. Asian investors are inclined towards investing in applications that have a clear path to monetization while Silicon Valley investors are open towards investing in deep technology of which the path to monetization is yet apparent. During the subsequent period, I saw two similar projects incubated and successfully launched via Ycombinator.
The way I managed to fix the three problems above was to acquire funds I didn’t yet have by taking up a day job while relocating the project to back to the Valley’s network. I count my blessings for having friends who lend a helping hand when I was in a crunch.
Self-doubt
I remembered having the conversation with the head of the incubator two years into the project during my visit back to Singapore when he tried to convince me the project was going nowhere and I should just throw in the towel. I managed to convince him and more importantly myself to give it go for another 6 months till the end of the year.
I remember the evenings and weekends alone in my room while not working on my day job. In between spurts of coding, I would browse through the web or sit staring at the wall trying to envision how product market fit would look like. As what Steve Jobs mentioned once in his lecture, it felt like pushing against a wall with no signs of progress or movement whatever so. If anything, it was a lot of frustration, self-doubt and dejection. A few times, I felt like throwing in the towel and just giving up. For a period of 6 months in 2014, I actually stopped touching the code in total exasperation and just left the project running on auto-pilot, swearing to never look at it again.
The hiatus was not to last long though. A calling is just like the siren, even if somewhat faint sometimes, it calls out to you in the depths of night or when just strolling along on the serene beaches of California. It was not long before I was back on my MacBook plowing through the project again with renewed vigor.
First signs of life
It was mid-2015, the project was still not showing signs of any form of traction. I had by then stockpiled some cash from my day job and was starting to get interested in acquiring a piece of real estate with the hope of generating some cashflow to bootstrap the project while freeing up my own time. It was during this period of time that I got introduced to my friend’s room mate who also happened to be interested in real estate.
We started meeting on weekends and utilizing GetData.IO to gather real estate data for our real estate investment purposes. We were gonna perform machine learning for real estate. The scope of the project was really demanding. It was during this period of dog fooding that I started understanding how users would use GetData.IO. It was also then when I realized how shitty and unsuited the infrastructure was for the kind and scale of data harvesting required for projects like ours. It catalyzed a full rewrite of the infrastructure over the course of the next two years as well as brought the semantic query language to maturity.
Technical challenges
Similar to what Max Levchin mentioned in the book Founder’s at work, during this period of time there was always this fear in the back of my mind that I would encounter technical challenges which would be unsolvable.
The site would occasionally go down as we started scaling the volume of daily crawls. I would spend hours on the weekends digging through the logs to attempt at reproducing the error so as to understand the root cause. The operations was like a (data) pipeline, scaling one section of the pipeline without addressing further down sections would inevitably cause fissures and breakage. Some form of manual calculus in the head would always need to be performed to figure out the best configuration to balance the volume and the costs.
The number 1 hardest problem I had to tackle during this period of time was the problem of caching and storage. As the volume of data increase, storage cost increase and so did wait time required before data could be downloaded. This problem brought down the central database a few times.
After procrastinating for a while as the problem festered in mid-2016, I decided that it was to be the number 1 priority to be solved. I spend a good 4 months going to big-data and artificial intelligence MeetUps in the Bay Area to check out the types of solutions available for the problem faced. While no suitable solutions were found, the 4 months helped elicit corner cases to the problem which I did not previously thought of. I ended up building my own in-house solution.
Traction and Growth
An unforeseen side effect of solving the storage and caching problem was its effect on SEO. The effects on SEO would not be visible until mid-2017 when I started seeing increased volume of organic traffic to the site. As load times got reduced from more than a minute in some cases to less than 400 milliseconds seconds, the volume of pages indexed by bots would increase, accompanied by increase in volume of visitors and reduction in bounce rates.
Continued education
It was in early-2016 that I came across an article expounding the benefits of reading widely and deeply by Paul Graham which prompted me to pick up my hobby of reading again. A self-hack demonstrated to me by the same friend, who helped relocated me here to the Bay Area, which I pursued vehemently got me reading up to 1.5 books a week. These are books which I summarized on my personal blog for later reference. All the learnings developed my mental model of the world and greatly aided in the way I tackled the project.
Edmodo’s VP of engineering hammered in the importance of not boiling the ocean when attempting to solve a technical problem, of always being judicious with the use of resource during my time working as a tech-lead under his wing. Another key lesson learned from him is that in some circumstances being liked and being effective do not go hand in hand. As the key decision maker, it is important to steadfastly practice the discipline of being effective.
Head of Design, Tim and Lukas helped me appreciate the significance of UX during my time working with them and how it ties to user psychology.
Edmodo’s CEO introduced us to mindfulness meditation late-2016 to help us weather through the turbulent times that was happening within the company then. It was rough. The practice which I have adopted till to date has helped keep my mind balance while navigating the uncertainties of the path I am treading.
Edmodo’s VP of product sent me for a course late-2017 which helped consolidate all the knowledge I have acquired till then into a coherent whole. The knowledge gained has helped greatly accelerated the progress of GetData.IO. During the same period, I was also introduced by him the Vipasanna mediation practice which coincidentally a large percentage of the management team practices.
One very significant paradigm shift I observed in myself during this period of continued education is the observed relationship between myself and the project. It has changed from an attitude of urgently needing to succeed at all cost to an attitude of open curiosity and fascination as one would an open ended science project.
Moving forward
To date, I have started working full time on the project again. GetData.IO has the support of more than 1,500 community members worldwide. Our mission is to turn the Web into the fully functional Giant Graph Database of Human Knowledge. Financially, with the help of our community members, the project is now self-sustaining. I feel grateful for all the support and lessons gained during this 6 year journey. I look forward to the journey ahead as I continue along my path.





